
Imagine if your AI assistant could understand you as well as your best friend—how close are we to that reality? Personalization of Large Language Models (LLMs) is an emerging field that aims to tailor these powerful AI systems to individual users, contexts, or tasks, significantly enhancing their relevance, accuracy, and overall performance. As reported by Forbes, this approach can streamline content production and reduce manual labor, while also improving user engagement and satisfaction across various applications. For example, personalized AI can revolutionize customer service by providing tailored responses, significantly reducing response times and enhancing customer satisfaction. Let’s dive into the key insights from the groundbreaking research by Zhang et al. on personalizing AI for you.
Personalization in LLMs
Personalization in the context of LLMs refers to the adaptation of these models to cater to individual users or specific groups, enhancing their ability to generate more relevant and tailored responses. But why does this matter for you as a user? This process aims to make LLMs more attuned to user preferences, characteristics, and needs, thereby improving the overall user experience and the model’s effectiveness in various applications. By incorporating user-specific information, personalized LLMs can maintain context over longer interactions, leading to more coherent and relevant responses across multiple queries or conversations. This approach not only enhances the natural feel of interactions but also has the potential to significantly improve performance in tasks such as product recommendations and content generation.
.
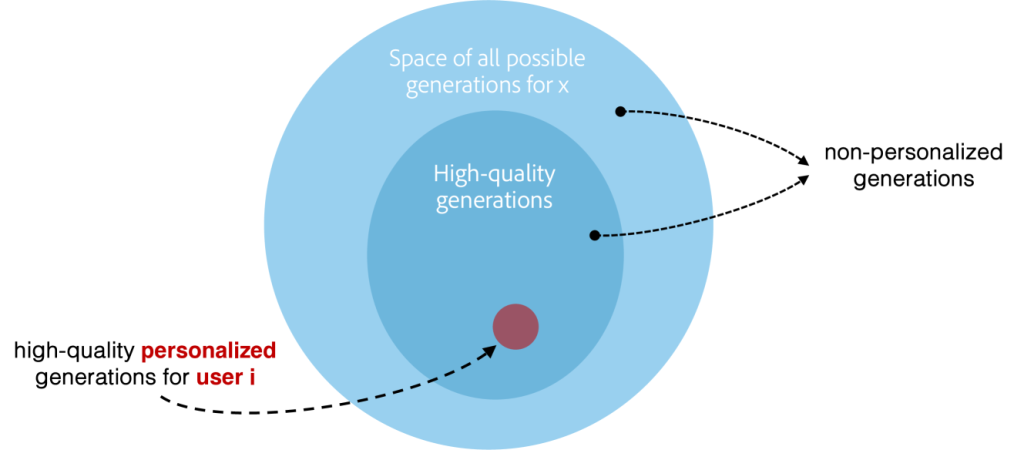
The accompanying image illustrates the concept of personalization in LLMs. It shows how the space of all possible responses can be progressively narrowed to focus on high-quality outputs. The largest circle, labeled „Space of all possible generations for x,“ represents all the potential responses a model could generate for a given prompt. The smaller circle within it, labeled „High-quality generations,“ depicts responses that are more coherent and relevant. Finally, the smallest red circle, „High-quality personalized generations for user i,“ highlights how personalization further hones in on the most relevant outputs tailored to an individual user’s preferences and context.
Personalization, as illustrated, has several advantages:
- Increased Relevance: By focusing on high-quality personalized generations, responses become highly specific to the user’s needs, improving overall relevance.
- Reduced Cognitive Load: Users spend less time filtering out irrelevant or generic information, making interactions more efficient.
- Improved User Satisfaction: Personalized outputs create a more intuitive and human-like experience, which enhances user satisfaction and engagement.
- Enhanced Consistency Over Time: Personalization helps maintain context across multiple interactions, fostering coherent conversations and a sense of continuity in user experience.
Thus, personalization effectively targets individual preferences, making LLMs particularly suitable for applications like personalized recommendations, content creation, and long-term conversational interactions.
Data Categories for Personalization
Personalization of Large Language Models (LLMs) relies on various data categories to tailor responses and improve user experiences. These categories encompass a wide range of information types, each contributing to a more comprehensive understanding of user preferences and contexts. Here’s an overview of the key data categories used for LLM personalization:
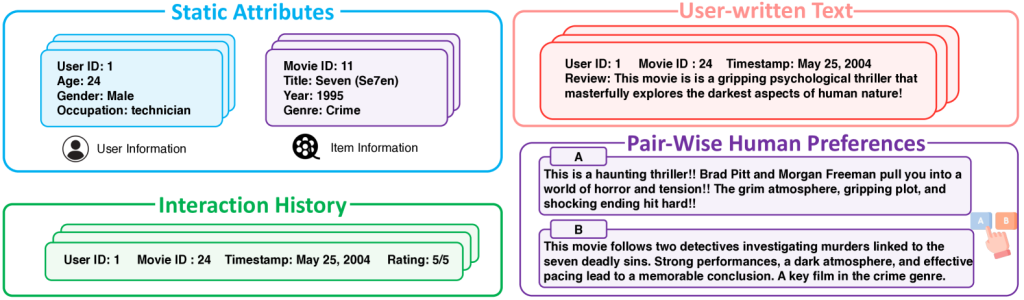
- Static Attributes: Relatively stable user information such as demographics, location, and professional background.
- Interaction History: Frequently changing information like browsing history, recent interactions, and current device usage.
- User-Written Text: User-generated content, chat logs, and written preferences providing insights into communication style and interests.
- Pair-Wise Human Preferences: Explicit user ratings, likes, or dislikes used to refine personalization strategies.
.
By integrating these diverse data categories, LLMs can create more accurate and nuanced personalization models, leading to enhanced user experiences across various applications. For instance, in e-commerce, using static attributes along with interaction history can help create highly targeted product recommendations that adapt to users‘ evolving preferences. However, it’s crucial to balance personalization efforts with privacy considerations and ethical data usage practices. However, it’s crucial to balance the use of personal data with privacy concerns and ethical considerations to ensure responsible AI development and deployment.
Granularity Levels Explained
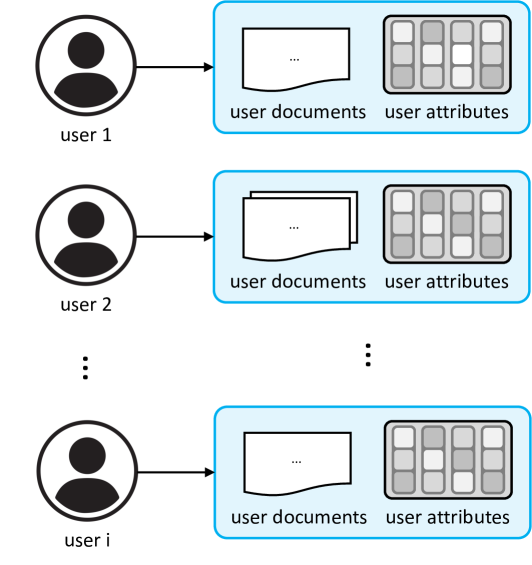
User-level personalization is about tailoring responses to a specific individual. For example, Spotify’s music recommendations are a great example of user-level personalization, where the service adapts playlists based on each user’s unique listening habits. It requires a deep understanding of that user’s preferences and behaviors, leading to highly customized experiences. However, this type of personalization often involves extensive data collection, which can raise privacy concerns.
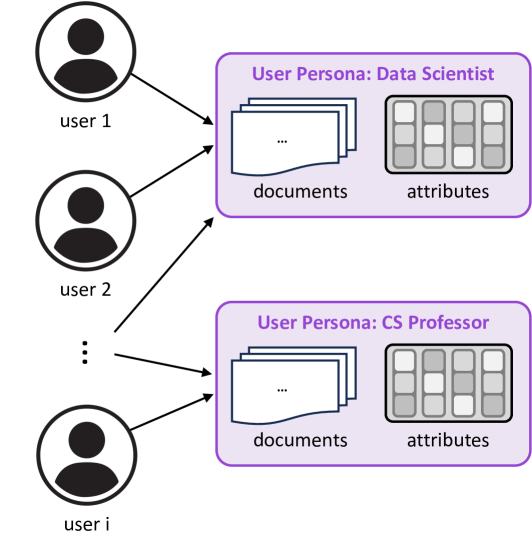
Group-level personalization, or persona-level personalization, targets a segment of users who share common characteristics. This approach allows for a good balance between personalization and scalability, since it avoids the complexity of individual-level personalization while still adapting to the needs of similar users.
Global preference personalization involves combining data from multiple users to identify general trends and preferences. This allows the model to leverage broader patterns, helping it generate responses that are well-suited to a large group of users.
Personalization Techniques Overview
Understanding these techniques can help us see how AI can be molded to meet individual needs. Personalization techniques for Large Language Models (LLMs) can be categorized based on how user information is utilized:
- Personalization via Retrieval-Augmented Generation (RAG): incorporates user information by using external knowledge bases, encoded through vectors. When new data arrives, relevant information is retrieved using similarity search, and this helps personalize the LLM’s response. This method is especially useful for retrieving personalized information in real time and supplementing the generation with user-specific details that cannot fit directly into the prompt.
- Personalization via Prompting: includes user information as context within prompts to influence the LLM’s output. By embedding user-specific or contextual information in prompts, LLMs can generate personalized responses. Techniques like contextual prompting, persona-based prompting, and profile-augmented prompting are used to incorporate user data effectively.
- Personalization via Representation Learning: encodes user information into embedding spaces. The user data can be represented through different parameters of the model, including full-parameter fine-tuning, parameter-efficient fine-tuning (PEFT), or specific embedding vectors. These embeddings capture individual preferences and characteristics, making model responses more tailored to the user.
- Personalization via Reinforcement Learning from Human Feedback (RLHF): uses user information as a reward signal to align LLMs with personalized preferences through reinforcement learning. This method refines the model’s responses based on user-specific feedback, aligning the model with diverse human preferences and making the interactions more personalized over time.
These techniques can be combined for optimal personalization, and the choice of method often depends on the use case, data availability, and privacy requirements.nt, potentially increasing efficiency and engagement. As the field of LLM personalization continues to evolve, researchers and practitioners are exploring innovative ways to combine these techniques for more effective and ethical personalization strategies.
Challenges in Personalizing LLMs
Personalizing large language models (LLMs) presents several challenges that researchers and developers must navigate to enhance user experiences effectively. But what makes personalizing AI so challenging? One significant hurdle is the cold-start problem, where models struggle to personalize outputs for new users with sparse data. This issue necessitates innovative strategies to adapt LLMs quickly without extensive user history.
Another challenge lies in privacy concerns, as personalization often requires access to sensitive user data. Balancing the need for personalized experiences with robust privacy protections is crucial, especially in an era of increasing data regulation. Additionally, bias mitigation is essential, as LLMs can inadvertently perpetuate biases present in their training data, leading to unfair treatment of users.
Moreover, implementing personalization at scale involves substantial infrastructure demands, as systems must handle increased computational loads and storage needs for vast user bases. Despite these challenges, the potential benefits of personalized AI are vast, making it a pursuit worth the effort. Finally, the integration of LLMs with other modalities and tools remains complex, requiring seamless coordination to deliver comprehensive personalized services. Addressing these challenges is vital for advancing the field of personalized LLMs and unlocking their full potential.
If you’d like to learn more or need guidance on how to personalize AI for your needs, or if you’re looking for a sparring partner to philosophize about this topic, feel free to get in touch with me.
Schreibe einen Kommentar